🧠 模型训练
🤖 Kuavo IL 是一个完整的机器人模仿学习框架,基于 LeRobot 构建,专为 Kuavo 人形机器人设计。该框架提供了从数据转换、模型训练到实际部署的完整工具链。
🎯 核心特性:
- 🔄 数据转换: 支持 ROS bag 到 LeRobot 格式的转换
- 🚀 一键训练: 提供数据转换与模型训练的一体化解决方案,支持多种策略模型(ACT, Diffusion)
- 🎮 实时部署: 支持训练模型在实际机器人上的实时推理和控制
- 📊 完整评估: 提供离线评估和在线部署的完整验证流程
🏗️ 项目架构:
kuavo-il-opensource/
├── kuavo/ # 核心功能模块
│ ├── kuavo_1convert/ # 数据转换工具
│ ├── kuavo_2train/ # 模型训练工具
│ ├── kuavo_3deploy/ # 模型部署工具
│ └── notebooks_check/ # 数据验证与可视化
└── lerobot/ # LeRobot 框架
🚀 快速开始
训练环境安装
- 克隆仓库
git clone https://gitee.com/leju-robot/kuavo-il-opensource.git
cd kuavo-il-opensource
- 创建虚拟环境
conda create -n kuavo_il python=3.10
conda activate kuavo_il
- 安装依赖
# 安装 LeRobot
pip install -e lerobot
🧠 模型训练
单卡训练
基础训练命令
- 进入项目根目录
cd kuavo-il-opensource
- 执行训练命令
python lerobot/lerobot/scripts/train.py \
--policy.type act \
--dataset.repo_id kuavo/Task0_example \
--dataset.local_files_only true \
--dataset.root kuavo/kuavo_1convert/Task0_example/v_example/lerobot/ \
--save_checkpoint true \
--batch_size 32 \
--num_workers 8 \
--output_dir kuavo/kuavo_1convert/Task0_example/v_example/ \
--steps 200000 \
--save_freq 20000 \
--log_freq 200
启用 WandB 监控(可选)
如果需要记录训练过程,可以加上--wandb.enable true --wandb.project Task0_example参数。另需在终端wandb login根据提示输入API key登录wandb账户。
python lerobot/lerobot/scripts/train.py \
--policy.type act \
--dataset.repo_id kuavo/Task0_example \
--dataset.local_files_only true \
--dataset.root kuavo/kuavo_1convert/Task0_example/v_example/lerobot/ \
--wandb.enable true \
--wandb.project Task0_example \
--save_checkpoint true \
--batch_size 32 \
--num_workers 8 \
--output_dir kuavo/kuavo_1convert/Task0_example/v_example/ \
--steps 200000 \
--save_freq 20000 \
--log_freq 200
若网络不允许实时上传wandb,可以在终端输入wandb offline,仍然使用--wandb.enable true --wandb.project Task0_example参数配置,这会把wandb存在模型输出目录里,之后查看可以wandb sync wand/latest-run/同步到wandb网站查看
参数说明
| 参数 | 描述 | 示例值 |
|---|---|---|
policy.type | policy类型(act/diffusion) | act |
dataset.repo_id | 从hf上拉数据需要,如果使用本地数据可以填<kuavo/TaskName> | kuavo/Task0_example |
dataset.local_files_only | 默认使用本地数据训练 | true |
dataset.root | 本地lerobot数据集路径 | kuavo/kuavo_1convert/Task0_example/v_example/lerobot/ |
save_checkpoint | 是否需要存储ckpt | true |
batch_size | 模型训练batch大小 | 32 |
num_workers | 数据加载使用cpu数量 | 8 |
output_dir | 模型输出目录 | kuavo/kuavo_1convert/Task0_example/v_example |
wandb.enable | 是否需要使用wandb记录训练过程,默认false | true |
wandb.project | 为本次训练过程命名 | Task0_example |
steps | 总训练采样batch次数,一般100000~200000 | 200000 |
save_freq | 每20000采样存储一次训练结果,可以取中间训练结果验证 | 20000 |
log_freq | 每200次采样log一次loss等数据显示到终端 | 200 |
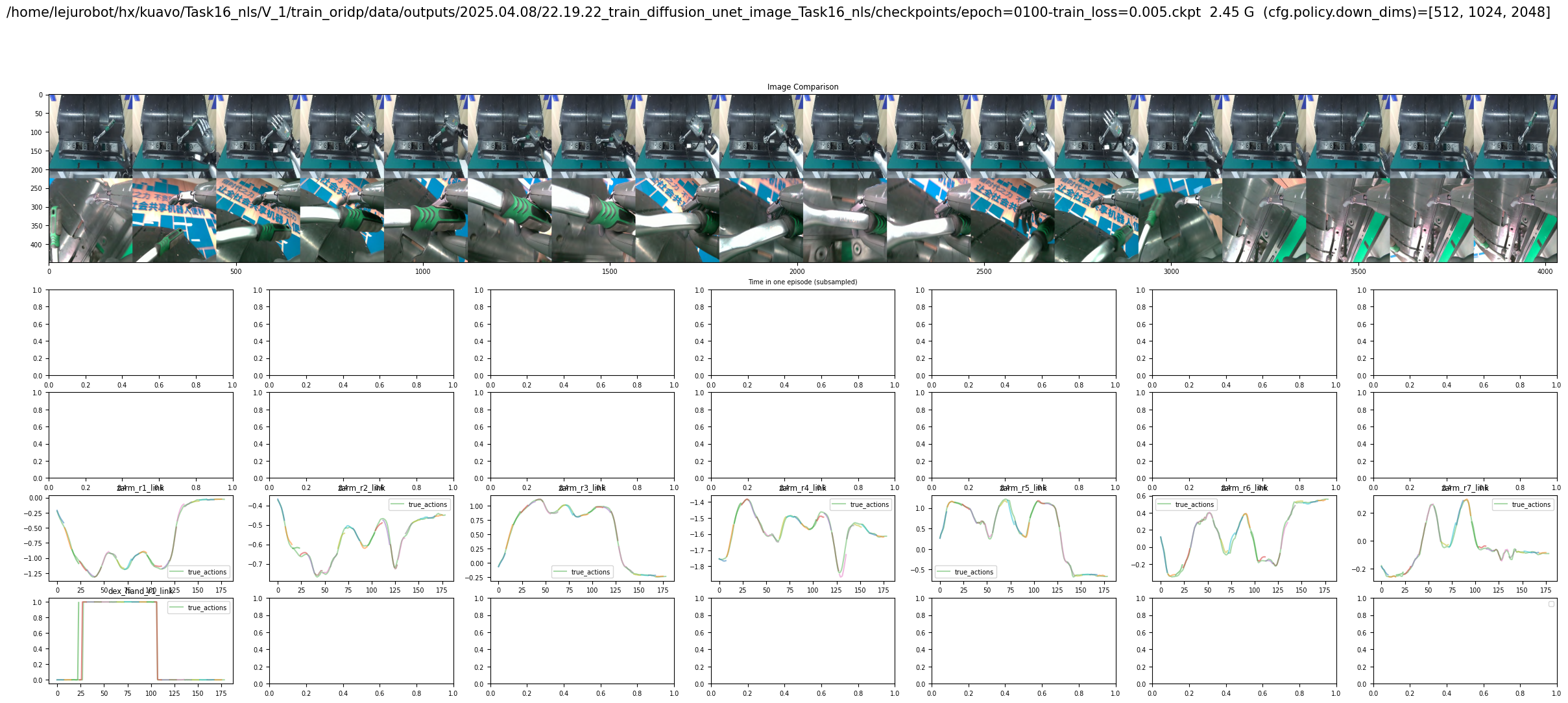
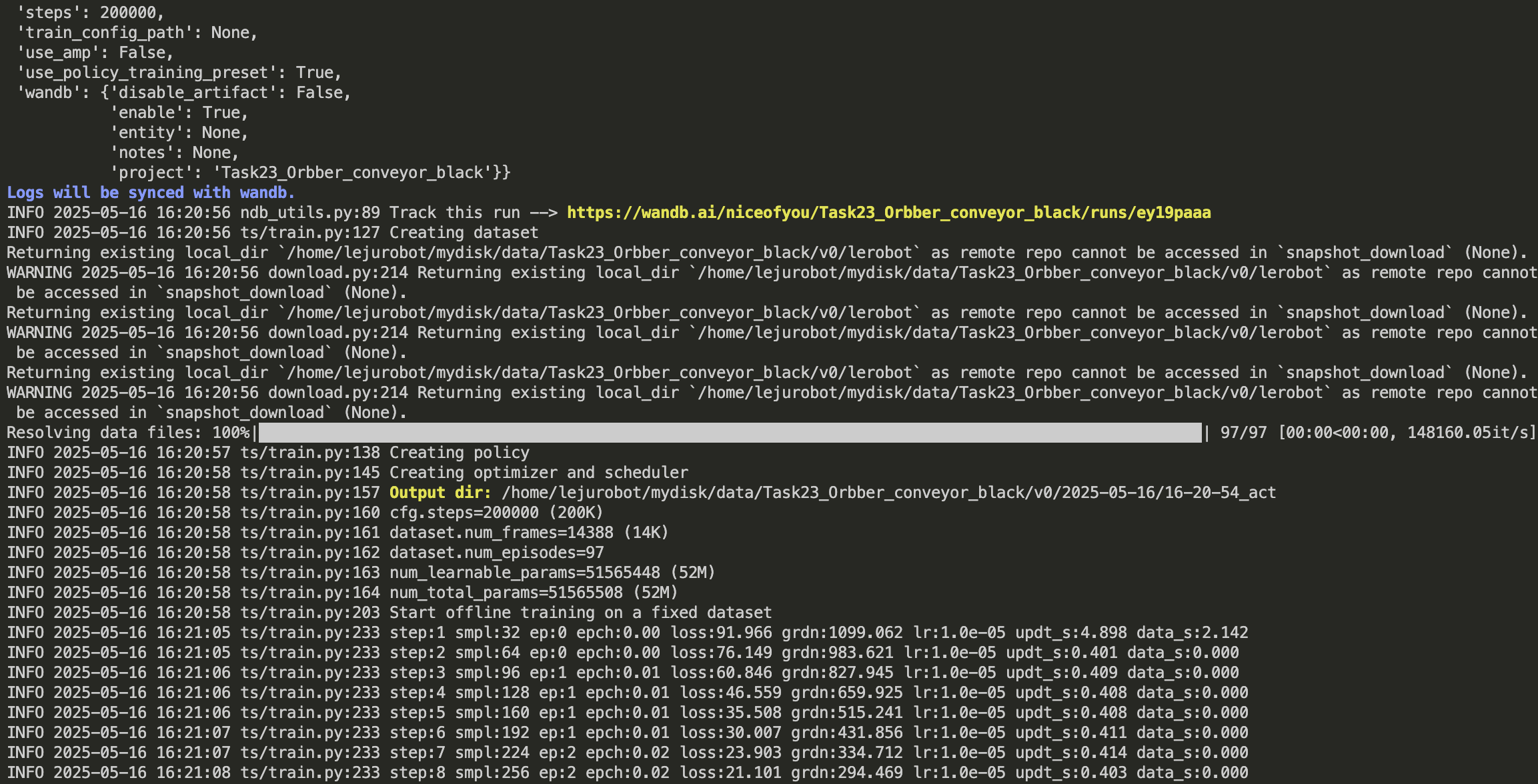
- 训练如下图所示
多卡分布式训练
基础分布式训练命令
- 进入项目根目录
cd kuavo-il-opensource
- 设置GPU环境并执行训练
# 示例命令,如果显卡数量大于 >=4,使用前4张GPU进行分布式训练。
export CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4
accelerate launch --num_processes=$GPUS --main_process_port 29399 --mixed_precision fp16 \
lerobot/lerobot/scripts/train_distributed.py \
--policy.type act \
--dataset.repo_id kuavo/Task0_example \
--dataset.local_files_only true \
--dataset.root kuavo/kuavo_1convert/Task0_example/v_example/lerobot/ \
--save_checkpoint true \
--batch_size 32 \
--num_workers 8 \
--output_dir kuavo/kuavo_1convert/Task0_example/v_example/ \
--epochs 500 \
--save_epoch 50
启用 WandB 监控(可选)
export CUDA_VISIBLE_DEVICES=0,1,2,3 GPUS=4
accelerate launch --num_processes=$GPUS --main_process_port 29399 --mixed_precision fp16 \
lerobot/lerobot/scripts/train_distributed.py \
--policy.type act \
--dataset.repo_id kuavo/Task0_example \
--dataset.local_files_only true \
--dataset.root kuavo/kuavo_1convert/Task0_example/v_example/lerobot/ \
--wandb.enable true \
--wandb.project Task0_example \
--save_checkpoint true \
--batch_size 32 \
--num_workers 8 \
--output_dir kuavo/kuavo_1convert/Task0_example/v_example/ \
--epochs 500 \
--save_epoch 50
分布式训练参数说明
| 参数 | 描述 | 示例值 |
|---|---|---|
num_processes | 训练时使用的GPU数量 | 3 |
main_process_port | 执行训练进程的端口号 | 29599 |
mixed_precision | 是否使用混合精度训练 | fp16 |
policy.type | policy类型(act/diffusion) | act |
dataset.repo_id | 从hf上拉数据需要,如果使用本地数据可以填<TaskName/lerobot> | kuavo/Task0_example |
dataset.local_files_only | 默认使用本地数据训练 | true |
dataset.root | 本地lerobot数据集路径 | kuavo/kuavo_1convert/Task0_example/v_example/lerobot/ |
save_checkpoint | 是否需要存储ckpt | true |
batch_size | 模型训练batch大小 | 32 |
num_workers | 数据加载使用cpu数量 | 8 |
output_dir | 模型输出目录 | kuavo/kuavo_1convert/Task0_example/v_example/ |
wandb.enable | 是否需要使用wandb记录训练过程,默认false | true |
wandb.project | 为本次训练过程命名 | Task0_example |
epochs | 训练轮数(数据集遍历一轮) | 600 |
save_epoch | 每50轮存储一次训练结果 | 50 |
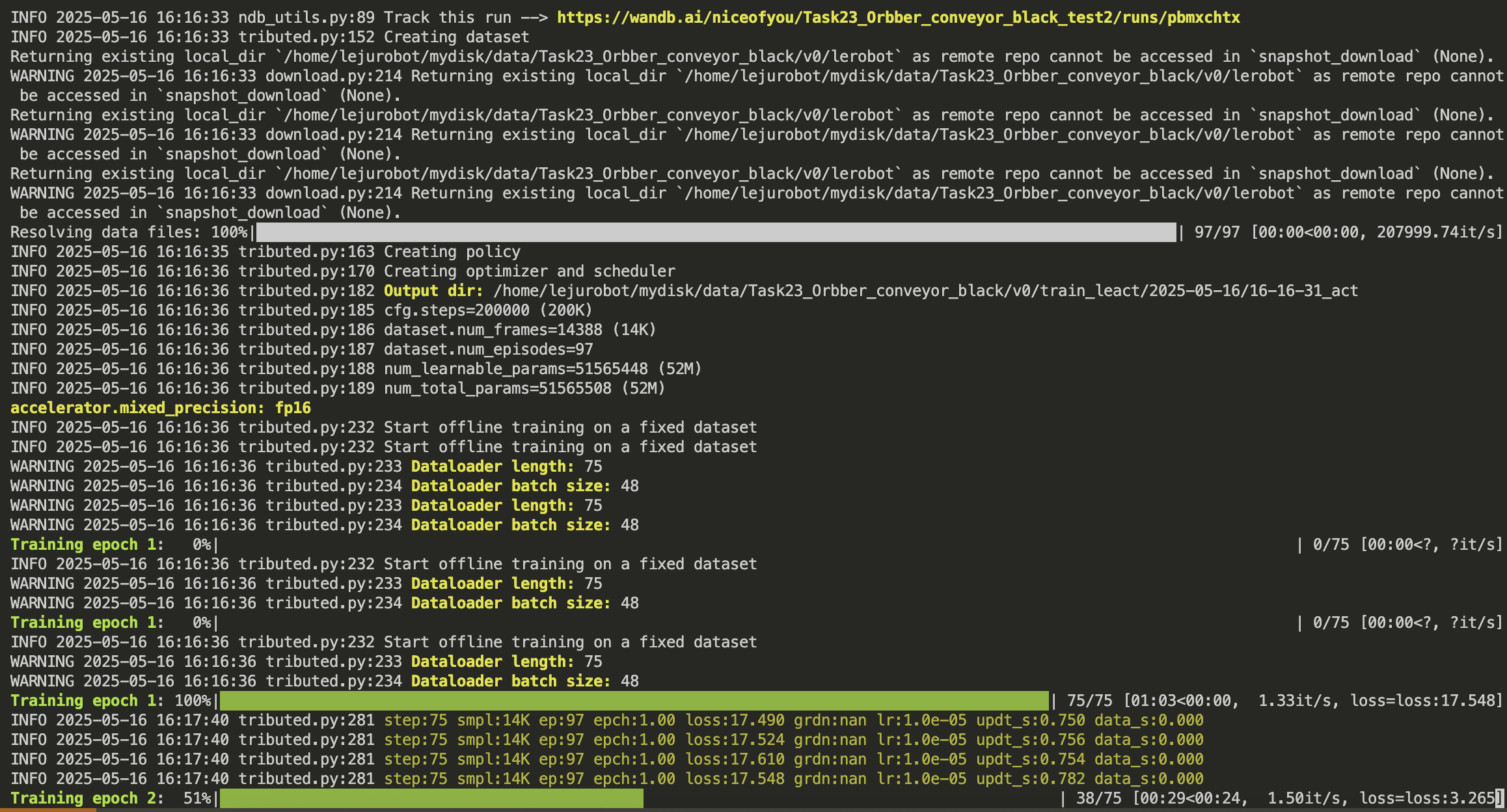
4.成功启动训练则显示下图
📊 性能评估(可选步骤)
离线评估
可以在训练的时候选取部分数据集不参与训练,转化为lerobot格式后进行离线评估作为初步模型的性能验证。
使用 Jupyter Notebook 进行离线评估:
进入 kuavo/notebooks_check/ 目录,打开 offlineEval_LeRobot.ipynb:
- 修改数据集路径和模型路径
class EvalConfig:
"""Evaluation configuration parameters"""
# Dataset configuration
dataset_root: str = "/Users/calmzeal/camille/code/kuavo_il/kuavo/kuavo_1convert/Task0_example/v_example/lerobot"
local_files_only: bool = True
# Model configuration
model_checkpoint_path: str = "/Users/calmzeal/camille/code/kuavo_il/kuavo/kuavo_1convert/Task0_example/v_example/2025-08-05/22-12-36_act/checkpoints/000010/pretrained_model"
# Evaluation configuration
selected_episodes_num: int = 4 # 需要可视化的episode数量
random_seed: int = 42
# Data preprocessing configuration
joint_slice_range: List[int] = field(default_factory=lambda: [0, 16]) # 模型输入的维度
fps: int = 10 # 模型训练时的帧率
# Noise configuration
image_noise_level: float = 0.0
state_noise_scale: float = 0.0
# Timestamp configuration - convenient for adjusting sensor data
camera_sensors: Dict[str, bool] = field(default_factory=lambda: {
"head_cam_l": False, # Enable head left camera
"wrist_cam_r": True, # Enable wrist right camera
"wrist_cam_l": True, # Enable wrist left camera
"head_cam_h": True, # Enable head main camera
})
# Visualization configuration
# [(0, 8), (13, 21)],表示左手和右手的关节组。如果是单手那么就只需要一个关节组,例如 [(0, 8)]
visualization_joint_groups: List[List[int]] = field(default_factory=lambda: [(0, 8), (13, 21)])
show_image_samples: int = 14 # 表示可视化图像的数量
# Device configuration
device: str = "cuda:0" if torch.cuda.is_available() else "cpu" - 运行所有单元格进行评估,最终绘图得到类似下图的离线评估结果(如图所示):