接入deepseek大模型语音交互案例
描述
- 接入deepseek大模型,实现了一个语音交互系统,包括录音、语音转写、对话生成和语音播放功能。
- 示例代码路径:
~/kuavo_ros_application/src/kuavo_large_model/kuavo_deepseek_model/rtasr_python3_demo.py
程序逻辑
- 导入模块及定义全局变量
- 作用:导入所需的Python标准库和第三方库并定义录音和音频处理的全局参数。
- RosAudioPublisher类
- 作用:初始化ros节点,创建音频数据发布器,向下位机传输数据流,使用外放设备播放音频
- publish_pcm_audio_data函数:将pcm文件按照int16格式发布audio_data话题。
- chat 函数
作用:实现录音功能,根据音量阈值和静默时间自动开始和结束录音。
关键逻辑:
使用 pyaudio 打开音频流并读取数据。
通过 audioop.rms 计算音频数据的音量。
如果音量超过阈值,开始录音;如果静默时间超过设定值,结束录音。
录音数据保存为PCM文件。
- deepseek_chat 函数
作用:调用deepseek_chat的API进行对话,并将回复通过TTS转换为语音播放。
关键逻辑:
构造请求体,发送到deepseek_chat的API。
解析API返回的回复内容。
调用 tts_xunfei 将回复转换为语音并播放。
- Client 类
作用:实现与讯飞实时语音转写(RTASR)服务的WebSocket通信。
关键逻辑:
初始化WebSocket连接并生成签名。
发送音频数据到RTASR服务。
接收并解析RTASR返回的转写结果。
- 主程序
作用:主程序逻辑,循环录音、转写、对话和播放。
关键逻辑:
调用 chat 录音。
使用 Client 类将录音发送到RTASR服务。
调用 deepseek_chat 进行对话并播放回复。
环境配置
上位机依赖安装
- 运行一键部署脚本
cd ~/kuavo_ros_application/src/ros_audio/kuavo_audio_player/scripts
chmod +x deploy_autostart_h12pro.sh
./deploy_autostart_h12pro.sh
- 安装额外依赖
# 安装音频相关系统库
sudo apt install -y portaudio19-dev python3-pyaudio
# 安装Python依赖(指定版本)
python3 -m pip install pyaudio==0.2.11 websocket-client==1.6.1
python3 -m pip install numpy==1.22.2 requests==2.31.0
说明
⚠️ 注意: 该案例使用了科大讯飞的RTASR,TTS模型以及深度求索(deepseek)的deepseek-chat模型。这三个模型均为收费模型,需要自行创建账号充值获取API Key并将获取到的API Key复制到程序对应地方,使用时机器人上位机要连接外网(能访问互联网)
该案例所使用的语音,文字转换模型为讯飞的模型: https://www.xfyun.cn/
- 讯飞实时语音转写(RTASR)模型
- 访问讯飞平台,选择语音识别-实时语音转写:https://console.xfyun.cn/services/rta,获取app_id和api_key
- 将程序
~/kuavo_ros_application/src/kuavo_large_model/kuavo_deepseek_model/rtasr_python3_demo.py第298,299行的app_id和api_key替换成获取到的即可
- 讯飞语音合成(TTS)模型
- 访问讯飞平台,选择语音合成-在线语音合成:https://console.xfyun.cn/services/tts,获取APPID,APISecret,APIKey
- 将程序
~/kuavo_ros_application/src/kuavo_large_model/kuavo_deepseek_model/tts_ws_python3_demo.py第139,140行的APPID,APISecret,APIKey替换成获取到的即可
- 讯飞实时语音转写(RTASR)模型
该案例所使用的对话大模型为深度求索(deepseek)推出的deepseek-chat: https://www.deepseek.com/
- 获取DeepSeek API Key:
- https://platform.deepseek.com/usage
- 充值,获取API Key
- 将程序
~/kuavo_ros_application/src/kuavo_large_model/kuavo_deepseek_model/rtasr_python3_demo.py第177行的api-key替换成获取到的即可
- 获取DeepSeek API Key:
执行
⚠️ 注意: 请保证上下位机ROS主从通信正常工作
- 下位机
cd kuavo-ros-opensource #进入下位机工作空间(根据实际部署目录切换)
sudo su
catkin build kuavo_audio_player
source devel/setup.bash
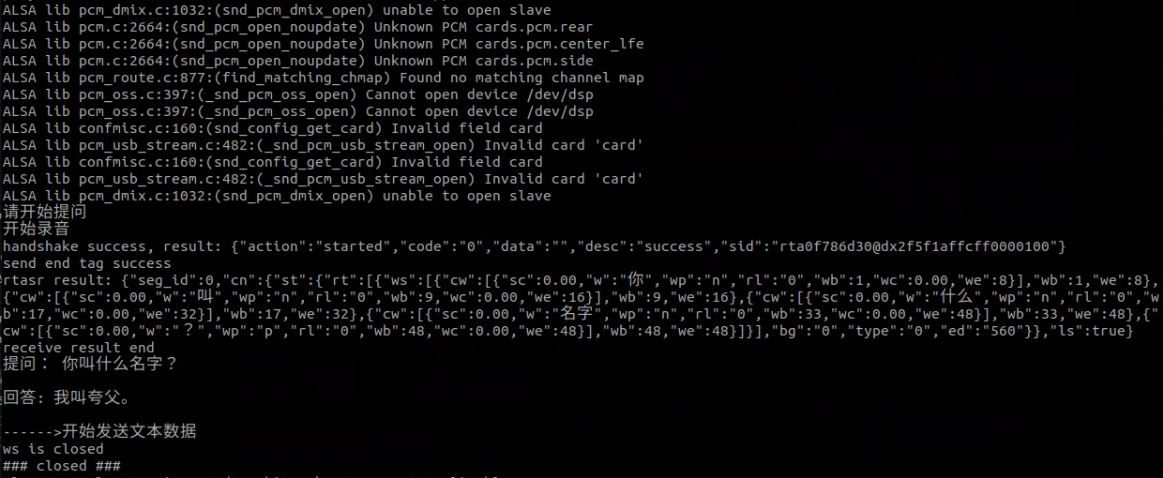
roslaunch kuavo_audio_player play_music.launch - 效果
- 上位机
cd kuavo_ros_application # 进入上位机工作空间(根据实际部署目录切换)
source /opt/ros/noetic/setup.bash
source devel/setup.bash
python3 src/kuavo_large_model/kuavo_deepseek_model/rtasr_python3_demo.py
- 效果